
By Myriam Jessier, SEO & Technical Brand Visibility Consultant (LLM & More)

As an avid reader, I always favor the written word. As a marketer, I see video as a strategic necessity, not a creative choice, when it comes to AI brand visibility. For humans, video offers emotional nuance. For machines, it provides a high-density stream of data points for indexing. If the hyperlink built the web, multimodal search is an emerging evolution. AI search is merging images, audio, and text into a single, machine-readable language.
Video as the “Trust Anchor”
Real-world human footage is the ultimate high-trust signal for machines. It provides physical evidence like a person speaking, a product in motion, or a specific location. AI-generated video often lacks the chaotic, non-repetitive entropy of real-world light and physics. It also comes with a watermark now since OpenAI and Google have integrated C2PA standards and SynthID watermarking. This helps real-world video stand out as a “ground truth” signal
Videos matter in two distinct modes:
- Training Mode: Brands with high volumes of consistent, transcribed video are “remembered” by models as authorities. Models encode the relationship between the brand (Entity A) and its expertise (Entity B).
- Generative Search Mode: Here, the LLM acts as an agent to retrieve answers for humans.
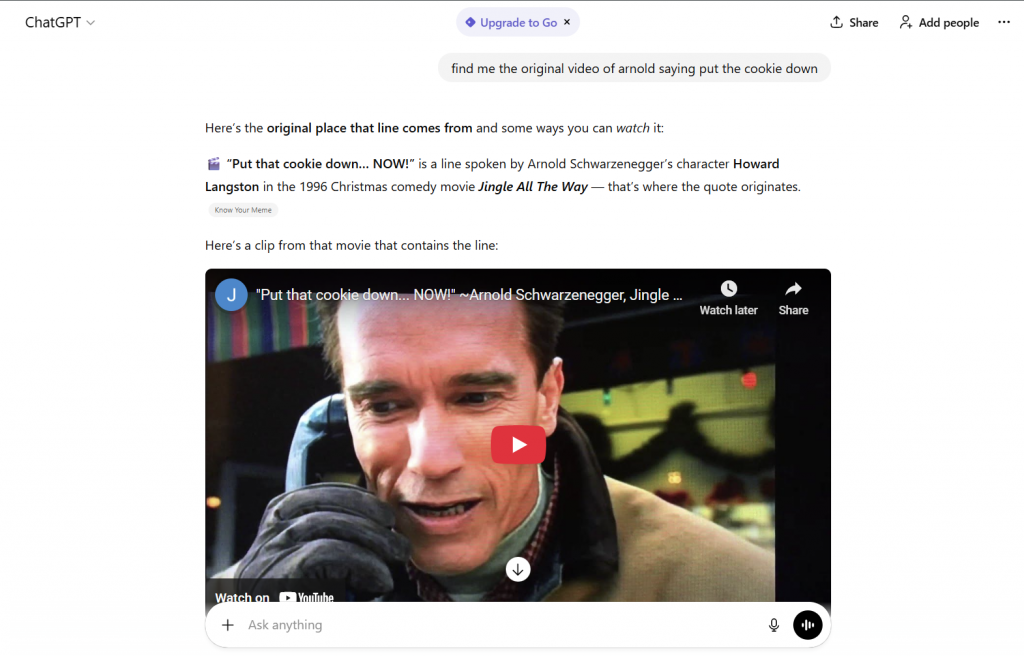
Check it here: https://chatgpt.com/share/695788af-e3bc-800d-b337-05074d5223d9
Currently, YouTube holds a functional monopoly on LLM video citations. Its transcript quality and Schema.org metadata are the cleanest for RAG. On top of that, high engagement signals (views and engagement) serve as proxies for quality. Meaning a brand without a YouTube presence may struggle being visible in a significant portion of AI queries.
Native vs. Simulated Understanding
How an AI “sees” your content depends on its architecture:
- Native Models (e.g., Gemini 1.5 Pro, GPT-5.2): These understand text, images, and audio simultaneously through discrete tokenization. They can perform “needle-in-a-haystack” retrieval. This means they can locate a specific event like Arnold screaming “put the cookie down”.
- Simulated Models: these “guess” what happens by matching sequences of static images against transcripts. They rely on frame sampling and textual surrogates.
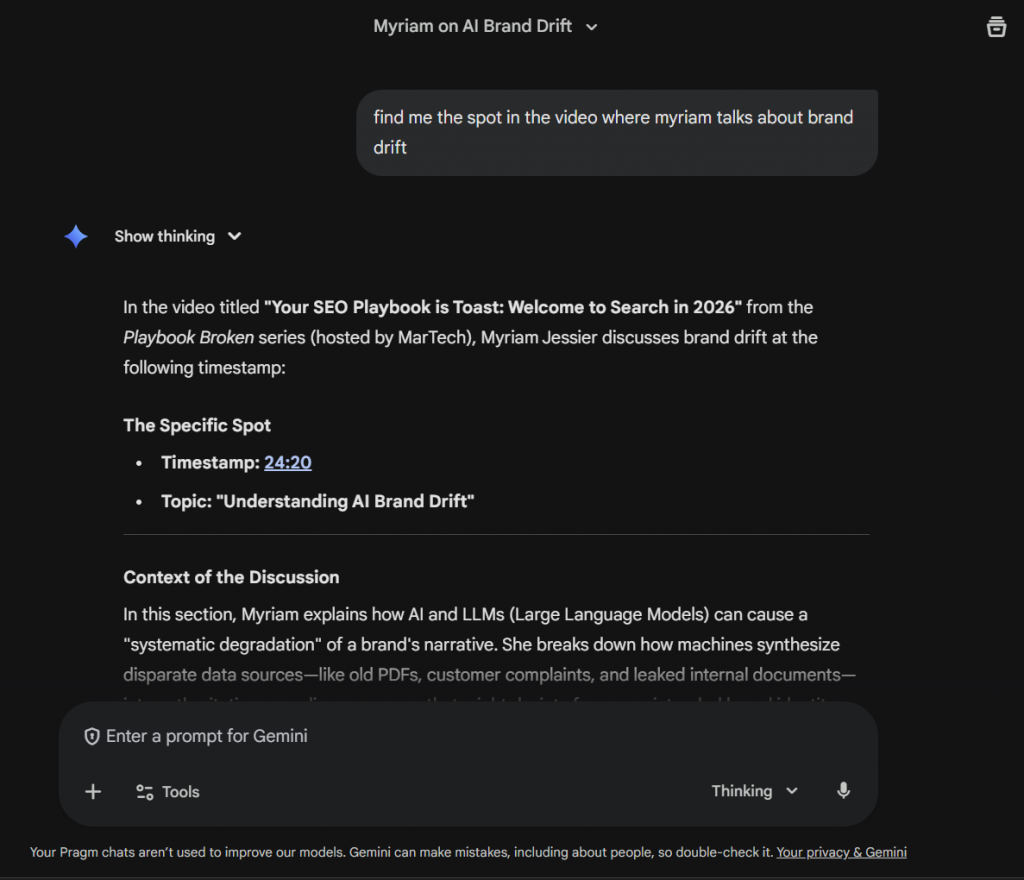
This is the difference between a model “knowing” your product works because it witnessed the event, versus “guessing” it works because the transcript said so.
The Three Layers of Machine-Readability
There are three layers: visual, audio and text.

1. The Visual Layer
Native models turn video into “visual words.” For non-native models, the focus is on object detection and Optical Character Recognition (OCR).
Optimization tips for the visual layer:
- Consistent brand codes, color palettes and logo placement help machine vision recognize the brand entity across different frames.
- Use high-contrast text overlays (lower-thirds) containing expert names.
- Ensure product labels are legible and face the camera.
2. The Audio Layer
This layer uses Automatic Speech Recognition (ASR) to convert speech to text. Advanced models also analyze the tone and cadence of the speaker. An authoritative tone serves as a “soft signal” of expertise.
Optimization tips for the audio layer:
- High-fidelity audio is a must. Any background noise or mumbled speech may mean corrupted transcripts.
- Ensure your visual and audio layers match; if you mention “Model X” but show “Model Y,” the ambiguity may cause the AI to discard the information.
3. The Text Layer
All models, even the native ones perform better when guided by structured signals. The transcript remains the primary data source for RAG systems. It acts as a bridge for models that cannot “watch” the content natively.
Optimization tips for the text layer:
- Provide human-verified transcripts and use VideoObject schema markup.
- Use the VideoObject schema markup to explicitly tell search engines what the video is about.
Fighting “Brand Drift”
When a brand’s presence in a training set is sparse, LLMs “interpolate”, making guesses based on industry averages. If 90% of your competitors offer a free trial but you don’t, the AI may hallucinate that you do. This is Brand Drift. Authoritative video allows you to provide “ground truth” assets that override internet rumors. A video of an expert explaining a complex topic contains nuances that a written blog post might miss. By producing content that fillsauthority gaps, you provide the proof needed to rectify an LLM’s understanding of your brand.
Note: GPT-5.2 has a knowledge cutoff of August 31, 2025, making it more resistant to “interpolating”, provided the brand has established high-trust visual signals.
Agentic AI: Video for Systems
An AI agent learning how to use a software tool will likely “watch” a video tutorial to understand UI interactions. Providing clear, step-by-step video content makes your product “agent-ready,” ensuring that as AI agents begin to execute tasks, they can navigate and recommend your services accurately.
How to get a handle on it
Video has transcended its role as a storytelling medium to become the essential data infrastructure for AI-narration. Video is a good type of content for social media engagement. It also doubles as a fundamental data source that preserves your brand visibility and authority. You can start repurposing your content to make videos, step one is to check Rosy Callejas’ BrightonSEO deck on the topic. Step two is to download the Whitepaper to know the strategy pros like T-Weiss rely on when it comes to video for AI search.