
By Jules de Bruin, Chief of Staff at Rankscale AI, co-authored with Hanns Kronenberg, Head of SEO at Chefkoch and creator of the Grounding Page Standard
225,340 Google Search Console impressions, 450 clicks, a 0.20% click-through rate (groundingpage.com, last 28 days).
107,000 impressions, 370 clicks, a 0.34% CTR (independent expat-information guide, launched in April 2026).
By any classical SEO scorecard, these are failures: visible to Google, almost never clicked. But that is only a failure if clicks are the only unit of value you measure.
Over the same windows, something else was happening.
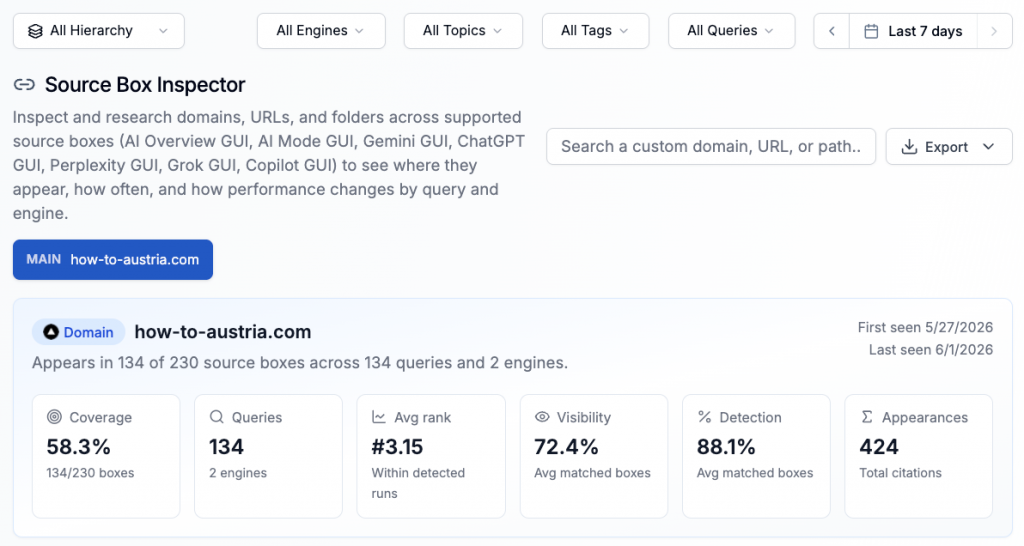
The first site received 26,285 hits from automated agents, 17,336 of them from ChatGPT-User, OpenAI’s on-demand fetch agent. The second site received 14,272 AI Search Engine hits in 12 days. For every one human Google click on the first site, roughly 58 machine fetches arrived.
Neither domain is relying on the kind of long-established domain authority that would normally explain this level of machine attention.
Think of these as About pages, but for every entity the brand cares about. Each product, each service, each regulation that matters. They exist for one reason: when AI describes one of those entities, it needs a source. These pages are that source.
They are packed with facts. Explicit numbers, dates, regulators, prices, named entities, attributions. Very little filler, persuasion, or brand voice. That density is what AI retrieval reaches for.
Microsoft: From Ranking Pages to Supporting Answers
In May 2026, Microsoft’s AI team published a blog post titled “Evolving role of the index: From ranking pages to supporting answers.”
This matters because Microsoft is not describing a fringe GEO theory. It is describing a structural shift in how modern search infrastructure supports AI answers.
The shift Microsoft described is simple. Traditional search asks: which pages should a user visit?
Grounding asks: what information can an AI system responsibly use to construct a response?
The unit of value has moved from the document to discrete, supportable facts with clear provenance. Stale facts produce wrong answers. Coverage gaps in high-value facts produce silence or hallucination.
Why This Matters: Four Ways AI Gets Your Entity Wrong
AI systems don’t just store and repeat brand facts. They reconstruct answers from model knowledge, retrieved web sources and probabilistic context.
When the facts about your entity are unclear, missing or inconsistent in the sources AI can reach, four structural failures appear.
Risk 1: Hallucinations. The model can’t find clear facts about your entity, so it fills the gap with plausible-sounding but wrong information. The user sees a confident answer. Your product or company is misrepresented.
Risk 2: Entity confusion. Brands, products, people, events and methods get confused with similar-named entities, with competitors, or with generic category descriptions. The fix is unambiguous disambiguation on a page the model can reach: “X is not Y; X is operated by Z; X is regulated under R.”
Risk 3: Non-inclusion. The model can’t find enough clear, trustworthy signals about your entity. So it may not include you in the answer at all, or mention you only briefly, with no description.
Risk 4: Language mismatch. Non-English entities can be underrepresented when AI systems retrieve disproportionately from English-language sources, or when no high-quality source exists in the user’s language. The result is not always a wrong answer. Sometimes it is absence. This matters especially for European brands.
The point of building dense, structured reference content is not to win clicks. It’s to give AI systems the source material they need to avoid each of these failures.
What “Information-Dense” Actually Looks Like
A practical contrast.
A typical homepage would state: “Rankscale helps companies unlock their AI Search potential.”
A high-density reference page would state: “Rankscale is an Austrian SaaS platform that measures brand visibility across generative AI search engines and provides prompt-level recommendations to improve AI visibility, operated by Rankscale GmbH, based in Vienna, Austria.”
The first sentence contains zero extractable facts. The second contains six. That’s the difference AI retrieval is responding to.
A dense reference page opens with a clear definition: what the entity is, who runs it, where it’s based. Then each sentence after carries extractable facts, named entities, numbers, dates, regulators, attributions. The density isn’t an aesthetic choice. It’s what makes the page legible to retrieval.
Several conventions codify these practices at the entity-page level: the Grounding Page Standard, structured fact-dense About pages, and Wikipedia-style entity articles.
The underlying property is the same across all of them: high information value per word, low noise per word.
In the dataset of this setup, OpenAI’s dedicated search-index agent (OAI-SearchBot) directed 38.5% of its activity at the entity reference pages and only 2.8% at the homepage. That is the clearest observed signal in the dataset that density beats navigational authority.
What This Piece Isn’t Claiming
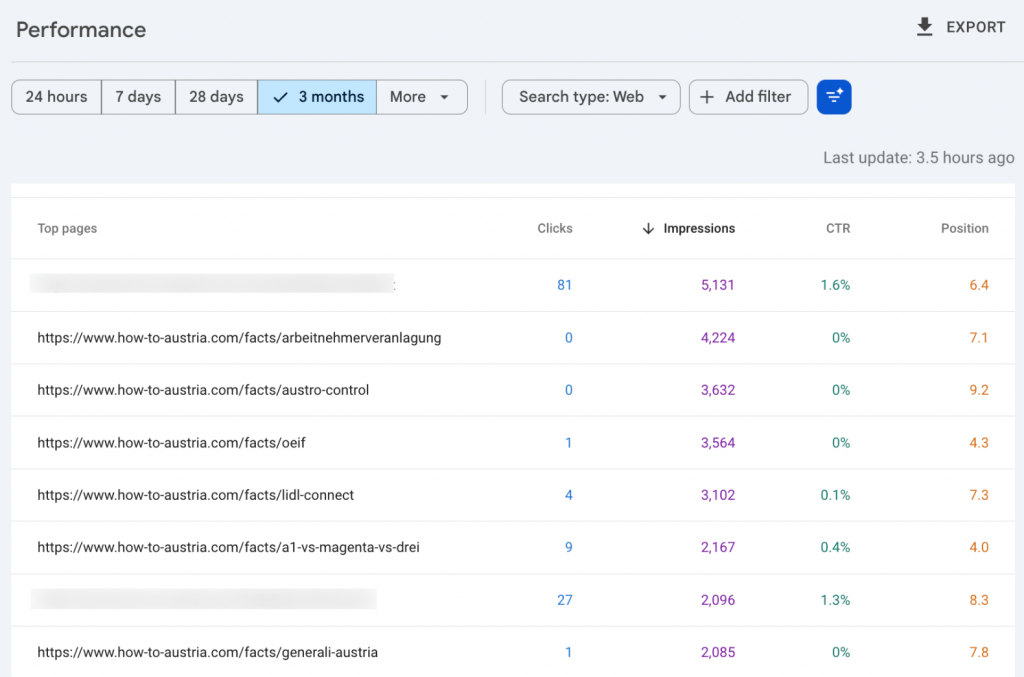
Entity reference pages are not the only kind of high-density page AI fetches. On the second site, broader in-depth buyer-intent guides received more total AI fetches than any single reference page. They are also dense, specific prices, named providers, regulatory references, comparison tables. AI fetches them for the same reason.
The two formats serve different patterns. Reference pages get fetched once per entity question. Guides get fetched again and again, because different buyer questions about the same topic each trigger a new fetch. Information density is the common factor across both.
High-density content is also brand-owned. GEO research consistently shows AI engines bias toward earned media, third-party authoritative sources. A dense page on your own domain helps a model interpret you correctly once it finds you. It doesn’t manufacture external authority on its own. Treat it as a complement to digital PR and third-party presence, not a substitute.
These insights are based on observable retrieval and citation patterns. No isolated, scientifically controlled experiment has been conducted.
How to Act on This
Three steps, in order:
1. Pick one high-stakes entity. Your category. Your flagship product. The regulation that affects your customers. The thing you want AI systems to describe correctly when a buyer asks.
2. Check what AI knows about it now, then close the gaps. Ask ChatGPT, Gemini, Perplexity, and Claude to describe the entity. Note what is missing, outdated, or confused with a competitor.
Then dedicate a new page to the entity, or rewrite an existing one. The test: every gap on your list should be answerable from the page in extractable form. One clear definition. Explicit numbers, dates, owners, regulators. Disambiguation against the things buyers confuse you with. Structured markup. Visible governance, owner, dateModified, changelog.
3. Watch your access logs. Filter for the named AI user agents: ChatGPT-User, OAI-SearchBot, ClaudeBot, Claude-User, PerplexityBot, GPTBot, Google-Extended, Bytespider. See which pages they actually fetch.
If AI is hitting the page you intended as the source for that entity, the density is working. If it’s hitting an off-target page, or no page at all, that’s where to add density next, or where the entity needs a dedicated reference page of its own.
The Takeaway
When AI describes you to a buyer, it is working from a page somewhere. The question is which page.
Either it’s one you wrote, dense with the stats and details the model can quote directly, or it’s whatever the model could scrape. And when AI is left to scrape, it can hallucinate. It takes cues from a competitor’s comparison page potentially including misrepresentation (we see a lot of weird statements about Rankscale on competitor’s pages). It leaves you out of the answer. It reaches for an English-language alternative because nothing in the right language exists.
Those are the four failure modes from earlier. Grounding pages exist to mitigate these risks. They don’t need to win a click. They need to be the source AI engines reach for when describing you.
If the page that should be doing that job doesn’t exist on your domain, you don’t have an SEO problem. You have an AI Grounding problem.
The homepage was never built for this job. It probably shouldn’t be asked to do it.
There is more to say about AI Grounding, but this is the core shift: the page that matters most may no longer be the one users click. It may be the one AI systems retrieve.
Feel free to connect on LinkedIn (Jules de Bruin & Hanns Kronenberg) or tap us on the shoulder about AI Grounding at one of the Berlin SEO & Content Club (BSCC) Meetups!